Building Kabir GPT a GPT-3 like model from Scratch
How I built a small character-level GPT-style transformer in PyTorch, trained on Kabir Das ke dohe. I start from a simple tokenizer and a bigram model, then slowly add context, positions, self-attention, multiple heads, transformer blocks, checkpointing, and text generation.
Building Kabir GPT from Scratch: A Decoder-Only Transformer for Kabir ke Dohe
About the output quality: The dohe and couplets this model generates are not perfect, and honestly they may not make much sense at all. The model has picked up the style of Kabir Das ji's dohe, but it cannot yet write couplets that actually mean something. This is just what I could manage with the compute I had. If I had access to something like an Nvidia H100 GPU, or even around $100 of cloud GPU credits, I could train a bigger model for longer and probably get much better results.
This is a learning project. It is a small GPT-style decoder-only transformer trained on Kabir Das ke dohe. I started with a character tokenizer and a basic bigram model, and then kept adding the pieces that real GPT models use: embeddings, position information, masked self-attention, multiple attention heads, residual connections, layer normalization, feed-forward layers, checkpointing, and text generation.
Introduction
Big language models look like magic from outside. You type something, the model replies, and it feels almost human. But underneath, the model is doing one simple job again and again: look at the previous text and guess the next piece of text.
I wanted to actually understand that, so I built a tiny version of it from scratch in PyTorch. I called it Kabir GPT because I trained it on Kabir's dohe (his couplets). I did not use any fancy pretrained tokenizer or a huge dataset. I kept it small and simple on purpose. It reads text one character at a time and learns to produce Kabir-style text the same way, character by character.
The point was never to build a real, production LLM. The point was to learn the full journey: how do you go from plain text in a file to a working transformer that generates new text?
Project Structure
kabir-llm/
├── data.txt # Training text: Kabir dohe
├── src/
│ ├── config.py # Model and training hyperparameters
│ ├── data_tokenize.py # Character tokenizer
│ ├── model.py # KabirGPT transformer model
│ ├── train.py # Training and checkpointing
│ └── inference.py # Text generation from saved checkpoint
├── pyproject.toml
└── README.md
The Core Idea
Kabir GPT is a character-level model that predicts text one character at a time.
In simple steps:
- Take the text and break it into characters.
- Turn each character into a number (a token id).
- Show the model a window of past characters.
- Ask it to guess the next character.
- While generating, add that guessed character back to the window.
- Repeat until we have enough new text.
In short, the training loop reads the dohe, tokenizes them, splits the data into train and validation sets, samples batches, runs them through the model to get predictions, measures how wrong they are with cross-entropy loss, backpropagates, updates the weights with AdamW, and saves the model whenever the validation loss improves.
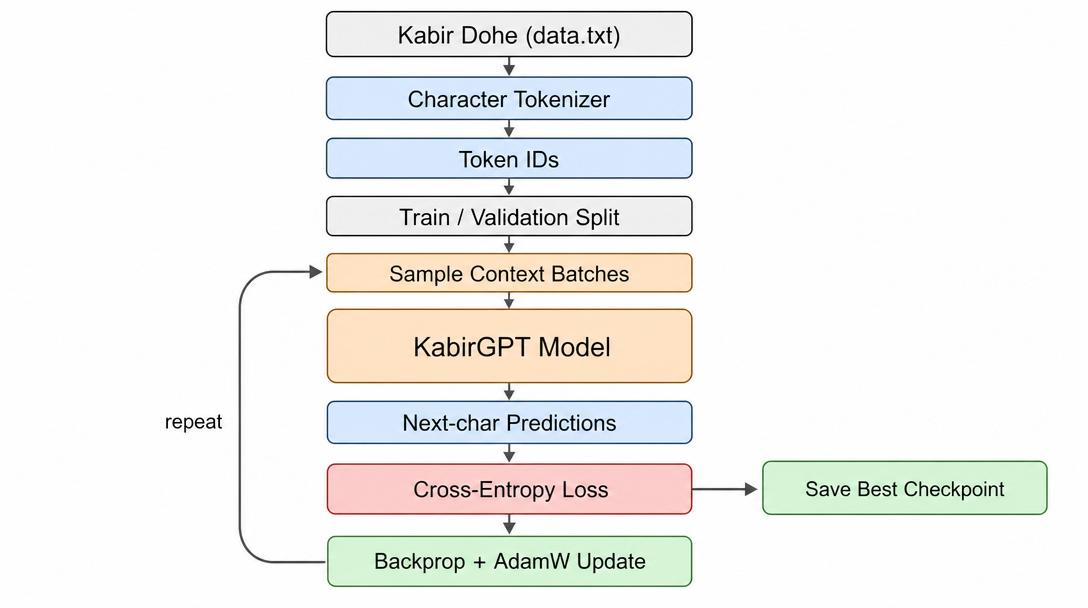
Model Architecture
Kabir GPT uses only the decoder half of the Transformer. There is no encoder. It uses masked self-attention, which just means it reads and writes text strictly from left to right and is never allowed to peek ahead.
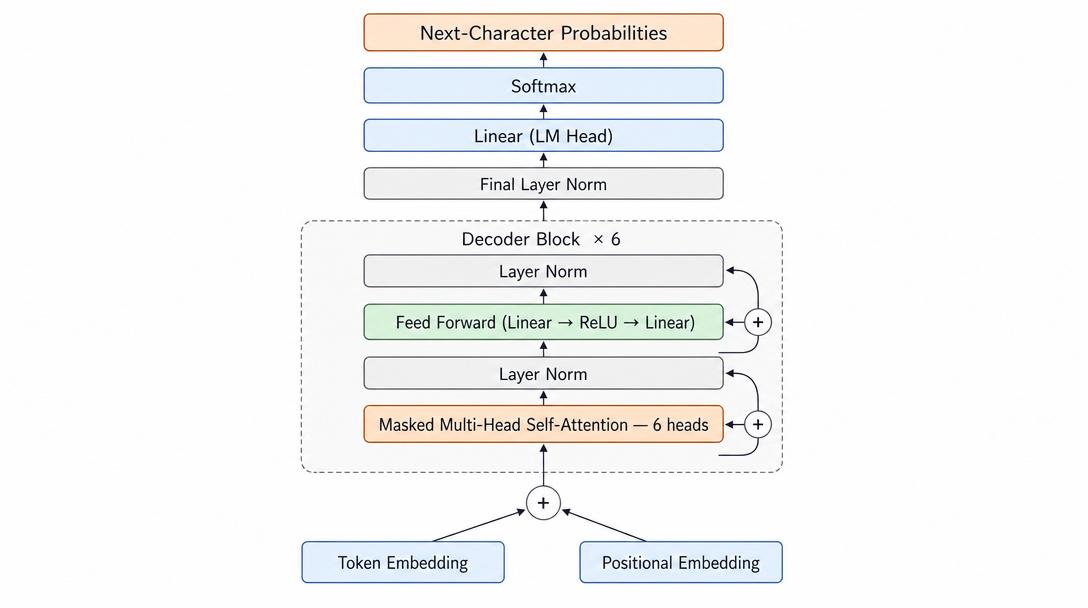
The flow is simple: each input character is turned into a token embedding, a position embedding is added on top, and the result passes through six stacked decoder blocks. Each block runs masked multi-head self-attention and a feed-forward network, both wrapped in layer normalization and residual connections. After the last block there is a final layer norm and a linear layer that produces the score for the next character.
These are the settings I used:
| Parameter | Value |
|----------|-------|
| Context size | 256 |
| Batch size | 64 |
| Embedding size | 384 |
| Attention heads | 6 |
| Transformer layers | 6 |
| Dropout | 0.2 |
| Optimizer | AdamW |
| Learning rate | 3e-4 |
| Train split | 90% |
Dependencies
The whole thing is Python and PyTorch. The model itself basically only needs torch.
import torch
import torch.nn as nn
from torch.nn import functional as F
One thing I cared about: I did not use any ready-made transformer library. The attention, the masking, the blocks, the loss, and the generation loop are all written by hand. That was the whole point, so I would actually understand each part.
Step 1: Character Tokenization
First I had to turn text into numbers, because the network cannot read characters directly. So every unique character in data.txt gets its own id.
In src/data_tokenize.py:
class DataTokenizer():
def __init__(self,data_path):
with open(data_path) as file:
self.text = file.read()
self.vocab = sorted(list(set(self.text)))
self.vocab_size = len(self.vocab)
self.stoi = {ch:i for i,ch in enumerate(self.vocab)}
self.itos = {i:ch for i,ch in enumerate(self.vocab)}
This gives me:
vocab: every unique character in the datastoi: character to numberitos: number to charactervocab_size: how many different characters exist
Then I convert the full text into a list of numbers:
def tokenize(self):
tokens = []
for c in self.text:
tokens.append(self.stoi[c])
return torch.tensor(tokens)
And later I can turn the model's numbers back into readable text:
def decode(self,tokens):
return "".join(self.itos[int(token)] for token in tokens)
Step 2: The Bigram Model
My first model was a very basic one called a bigram model.
A bigram model guesses the next character using only the current one. So if the current character is क, it just learns which character usually comes after क.
I started here because it is the smallest thing that still proves the full pipeline works:
- Load the data.
- Tokenize it.
- Make batches.
- Run the model forward.
- Compute loss.
- Backpropagate.
- Generate some text.
This model is weak because it has almost no memory. It cannot understand a line or a full doha. It only ever looks at one character. But that is fine, it gave me a clean, working starting point to build on.
Step 3: Adding Context and Positions
The next step was to stop looking at one character and start looking at a whole window of past characters.
In src/config.py:
CONTEXT_SIZE = 256
BATCH_SIZE = 64
The training code grabs chunks of length CONTEXT_SIZE. For each input x, the target y is just the same chunk shifted by one character:
def get_batches(mode):
data = train_data if mode.lower()=="train" else test_data
ix = torch.randint(len(data)-CONTEXT_SIZE,(BATCH_SIZE,))
x = torch.stack([data[i:i+CONTEXT_SIZE]for i in ix])
y = torch.stack([data[i+1:i+CONTEXT_SIZE+1]for i in ix])
return x.to(DEVICE),y.to(DEVICE)
So it looks like:
x = [क, ब, ी, र]
y = [ब, ी, र, ...]
At every spot, the model predicts the character that comes next.
But there is a catch. If I only use character embeddings, the model knows what each character is but not where it sits in the line. So I also added position embeddings:
self.token_embedding_table = nn.Embedding(vocab_size,N_EMBED)
self.pos_embedding_table = nn.Embedding(CONTEXT_SIZE,N_EMBED)
And in the forward pass I just add the two together:
tok_embedings = self.token_embedding_table(idx)
pos_embedding = self.pos_embedding_table(torch.arange(T, device=idx.device))
x = tok_embedings+pos_embedding
Now the model knows both the character and its position.
Step 4: Masked Self-Attention
Self-attention is what lets each character look at the other characters in the window and decide which ones matter.
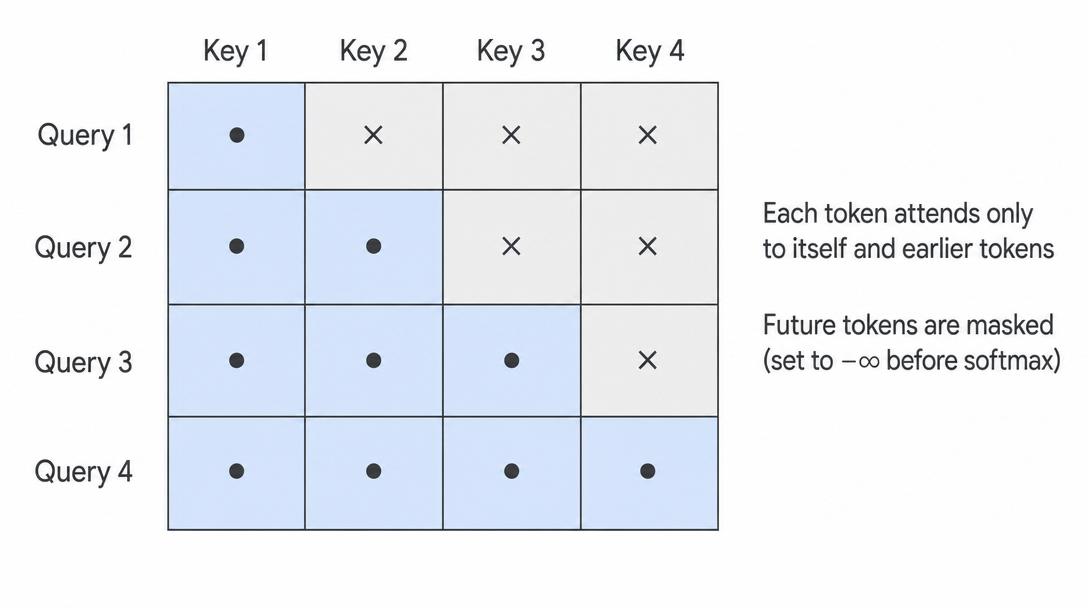
For generating text, there is one strict rule: the model must not look into the future. When it is predicting character number t, it can only use characters 0 to t.
To enforce that, the attention uses a causal mask:
self.register_buffer('tril',torch.tril(torch.ones(CONTEXT_SIZE,CONTEXT_SIZE)))
Inside attention:
wei = q@ k.transpose(-2,-1) * k.shape[-1]**-0.5
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
This makes a triangle pattern where each token can only see itself and the ones before it. Token 4 can look at tokens 1, 2, 3, and 4. Token 2 can only look at 1 and 2. This is exactly what stops the model from cheating, and it is why it can generate text left to right.
Step 5: Multi-Head Attention
One attention head gives the model one way of looking at the context. With multiple heads, the model can look at the same text in several different ways at once.
In src/model.py:
class MultiHeadAttention(nn.Module):
def __init__(self,num_head,head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_head)])
self.projection = nn.Linear(N_EMBED,N_EMBED)
self.dropout = nn.Dropout(DROPOUT)
Each head works on the same input on its own, and then I join their outputs:
out = torch.cat([h(x) for h in self.heads],dim=-1)
out = self.dropout(self.projection(out))
With N_HEAD = 6, every block in Kabir GPT has six heads.
Step 6: Feed-Forward Network
After attention, each character's representation goes through a small two-layer network:
class FeedFwd(nn.Module):
def __init__(self,n_embed):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embed, 4 * n_embed),
nn.ReLU(),
nn.Linear(4 * n_embed,n_embed),
nn.Dropout(DROPOUT)
)
The way I think about it: attention mixes information between characters, and this feed-forward part then works on each character on its own and gives the model more room to actually learn patterns.
Step 7: Transformer Blocks
A full decoder block just stacks these pieces together:
- Layer normalization
- Masked multi-head attention
- A residual (skip) connection
- Layer normalization again
- Feed-forward network
- Another residual connection
In code:
class Block(nn.Module):
def __init__(self,n_embed,n_head):
super().__init__()
head_size = n_embed//n_head
self.self_attn = MultiHeadAttention(n_head,head_size)
self.feed_fwd = FeedFwd(n_embed)
self.ln1 = nn.LayerNorm(n_embed)
self.ln2 = nn.LayerNorm(n_embed)
def forward(self,x):
x = x + self.self_attn(self.ln1(x))
x = x + self.feed_fwd(self.ln2(x))
return x
This is a "pre-norm" block, which just means the normalization happens before attention and before the feed-forward part. The x = x + ... lines are the residual connections, which let the original input flow through untouched and make deeper models much easier to train.
The full model stacks six of these:
self.blocks = nn.Sequential(
*[Block(N_EMBED,n_head=N_HEAD) for _ in range(N_LAYER)],
nn.LayerNorm(N_EMBED)
)
Step 8: The KabirGPT Forward Pass
The forward pass is short, but this is basically the whole model:
def forward(self,idx,targets=None):
B,T = idx.shape
tok_embedings = self.token_embedding_table(idx)
pos_embedding = self.pos_embedding_table(torch.arange(T, device=idx.device))
x = tok_embedings+pos_embedding
x = self.blocks(x)
logits = self.lm_head(x)
If I pass in the targets, it also computes the training loss:
if targets == None:
loss = None
else:
B,T,C = logits.shape
logits = logits.view(B*T,C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits,targets)
The logits are basically the model's scores for what the next character should be, for every position in the batch.
Step 9: Training and Checkpointing
I trained it with AdamW:
model = KabirGPT(vocab_size).to(DEVICE)
optim = torch.optim.AdamW(model.parameters(),lr=LEARNING_RATE)
Every now and then I check the train and validation loss:
@torch.no_grad()
def estimate_loss():
out = {}
model.eval()
for split in ['train', 'val']:
losses = torch.zeros(EVAL_ITERS)
for k in range(EVAL_ITERS):
X, Y = get_batches(split)
logits, loss = model(X, Y)
losses[k] = loss.item()
out[split] = losses.mean()
model.train()
return out
Whenever the validation loss gets better, I save that version of the model:
if current_val_loss < best_val_loss:
best_val_loss = current_val_loss
EXPORT_DIR.mkdir(parents=True, exist_ok=True)
torch.save(
{
"iter": iter,
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optim.state_dict(),
"train_loss": losses["train"].item(),
"val_loss": current_val_loss,
"vocab_size": vocab_size,
},
BEST_MODEL_PATH,
)
The saved model goes here:
exported-model/best_model.pt
I save the best model by validation loss instead of just the last one, because the last training step is not always the best version of the model.
Step 10: Generating Text
Generation starts from a single character and keeps guessing the next one.
In KabirGPT.generate:
def generate(self, idx, max_new_token):
for _ in range(max_new_token):
idx_cond = idx[:, -CONTEXT_SIZE:]
logits, loss = self(idx_cond)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next), dim=1)
return idx
The key line is this one:
idx_cond = idx[:, -CONTEXT_SIZE:]
Even when the generated text keeps growing, the model only ever looks at the last CONTEXT_SIZE characters.
The inference script loads the best saved model:
checkpoint = torch.load(model_path, map_location=DEVICE)
state_dict = checkpoint.get("model_state_dict", checkpoint)
model.load_state_dict(state_dict)
model.eval()
And then generates:
with torch.no_grad():
start_token = torch.zeros((1,1), dtype=torch.long, device=DEVICE)
output = model.generate(start_token, max_new_token=GENERATE_TOKENS)
print(tokenizer.decode(output[0].tolist()))
Running the Project
Install dependencies:
uv sync
Train the model:
uv run python src/train.py
Generate text from the saved model:
uv run python src/inference.py
What I Took Away From This
-
A language model is just next-character (or next-token) prediction. Once that clicked, the rest made a lot more sense.
-
Tokenizing is how text becomes numbers. Even a simple character tokenizer is enough to train a small model.
-
Position information matters. Without it, the model has no idea about the order of the characters.
-
Masking stops the model from cheating. During training it must not be able to see future characters.
-
Multiple heads give multiple points of view. Different heads can pick up on different relationships in the text.
-
Residual connections and LayerNorm make training stable. They make it much easier to stack more layers.
-
Saving the best model beats saving the last one. The final step is not always the best.
What It Would Take to Make This Better
This is a learning project, so it is small on purpose. To push it further I would want:
- More data. More dohe would make the output far more coherent.
- A better tokenizer. Something like byte-pair encoding would be more efficient than going character by character.
- Saved sample outputs. Writing out generated text at each checkpoint would make progress easier to see.
- Sampling controls. Things like temperature and top-k / top-p would give more control over the output.
- Loss logging. Plotting the loss curves would make debugging much easier.
- Config saved with the model. Storing the settings along with the checkpoint would make inference safer if I change hyperparameters later.
Conclusion
Kabir GPT started as a plain tokenizer and a bigram model, and slowly grew into a full decoder-only transformer. Building it one step at a time is what finally made the architecture click for me.
The biggest takeaway is that a GPT-style model is not one scary magic box. It is just a stack of understandable parts: token embeddings, position embeddings, masked self-attention, feed-forward layers, residual connections, layer normalization, and predicting the next character.
Once you connect those pieces, the model can learn from Kabir's dohe and write new Kabir-style text, one character at a time.
Built with PyTorch, Kabir ke dohe, and a lot of curiosity.